指令系统
| 操作码 | 地址码(操作数的地址) |
|---|
组成:一条指令由操作码和操作数组成。
执行过程:取指令——分析指令——执行指令
指令寻址方式:
- 顺序寻址
- 跳跃寻址
指令操作数寻址方式:
- 立即寻址
- 直接寻址
- 间接寻址
- 寄存器寻址
- 基址寻址
- 变址寻址
指令集
CISC:复杂指令系统。兼容性强,指令繁多、长度可变,由微程序实现。
RISC:精简指令系统。指令少,使用频率接近,主要依靠硬件实现(通用寄存器硬布线逻辑控制)。
Flynn分类法
Flynn分类法根据“指令流、数据流”及其多倍性,将计算机系统分为四类:
- 单指令流单数据流(SISD)
- 单指令流多数据流(SIMD)
- 多指令流单数据流(MISD)
- 多指令流多数据流(MIMD)现主流多核计算机俗语MIMD
指令流水线(精简指令集使用)
由于指令执行过程分多个阶段,每段由不同的部分区处理,采用流水线可以节省时间:
RISC:
- 超流水线技术(Super Pipe Line):时间换空间
- 超标量技术(Super Scalar):空间换时间
- 超长指令字技术(Very Long Instruction World,VLIW):发挥软件作用
流水线时间计算
周期:指令分成不同执行段,其中执行时间最长的段为流水线周期。
执行时间:*1条指令总执行时间+(总指令条数-1)流水线周期
吞吐率计算:吞吐率即单位时间内执行的指令条数。公式:指令条数/流水线执行时间。
加速比计算:加速比即使用流水线后的效率提升度,即比不使用流水线快了多少倍,越高表明流水线效率越高,公式:不使用流水线执行时间/使用流水线执行时间。
例题
例题①:
流水线的吞吐率是指流水线在单位时间里所完成的任务数或输出的结果数。设某流水线有5段,有1段的时间为2ns ,另外4段的每段时间为1ns,利用此流水线完成100个任务的吞率约为()
个/s。
A.500x10^6 B.490x10^6 C.250x10^6 D.167x10^6
答案:B
解析:注意单位为秒s,1s=10^9ns,可知流水线周期为2ns,指令条数为100,流水线执行时间为:[6+(100-1)x2],因为吞吐率=指令条数/流水线执行时间,所以吞吐率为:
{100/[6+(100-1)x2]}x10^9
=(100/204)x10^9
≈0.49x10^9
=490x10^6
例题②:
假设磁盘块与缓冲区大小相同,每个盘块读入缓冲区的时间为15us,由缓冲区送至用户区的时间是5us,在用户区内系统对每块数据的处理时间为1us,若用户需要将大小为10个磁盘块的Doc文件逐块从磁盘读入缓冲区,并送至用户区进行处理,那么采用单缓冲区需要花费的时间为()us;采用双缓冲区需要花费的时间为()us。
A.150 B.151 C.156 D.201
A.150 B.151 C.156 D.201
答案:D、C
解析:该流程分成了三个步骤,可以看作流水线来计算,前两步骤都依赖缓冲区,所以在单缓冲时看成一步合并前两步:(15+5=20us),运行时间=21+(10-1)x20=201us。双缓冲区正常计算运行时间为=21+(10-1)x15=156us。
例题③:
流水线技术是通过并行硬件来提高系统性能的常用方法。对于一个k段流水线,假设其各段的执行时间均相等(设为t),输入到流水线中的任务是连续的理想情况下,完成n个连续任务需要的总时间为()。若某流水线浮点加法运算器分为5段,所需要的时间分别是6ns、7ns、8ns、9ns和6ns,则其最大加速比为()。
A.nkt B.(k+n-1)t C.(n-k)kt D.(k+n+1)t
答案:B
解析:套公式,运行周期为9,一次运行(6+7+8+9+6)=36ns,流水线运行时间为=36+(n-1)x9,不用流水线运行时间:36n,加速比为:不用流水线运行时间/流水线运行时间=36n/36+(n-1)x9,化简为:4n/(n-3),利用极限的思想,结果逼近为4。
存储系统
- CPU内部:通用寄存器
- Cache
- 主存储器
- 联机磁盘存储器
- 脱机光盘、磁盘存储器
分级存储:解决存储容量、成本、速度之间的矛盾
两级存储:Cache-主存、主存-辅存(虚拟存储体系)。
局部性原理:总的来说,在CPU运行时,所访问的数据会趋向于一个较小的局部空间地址内,包括下面两个方面:
- 时间局部性原理:如果一个数据项正在被访问,那么在近期它很可能会被再次访问,即在相邻的时间里会访问同一个数据项。
- 空间局部性原理:在最近的将来会用到的数据的地址和现在正在访问的数据地址很可能是相近的,即相邻的空间地址会被连续访问。
高速缓存Cache
Cache用于储存最活跃的程序和数据,直接和CPU交互,位于CPU和主存之间。
Cache由控制部分和存储器组成。存储器存储数据,控制部分判断CPU访问数据是否在Cache中,在则命中,不在则依据一定算法从主存中替换。
Cache地址映射(由硬件自动完成)
在CPU工作时,送出的是主存单元的地址,而应从Cache存储器中读/写信息。这就需要将主存地址转换为Cache存储器地址,这种地址的转换称为地址映像,由硬件自动完成映射,分三种方法:
直接映射
全相联映射(不浪费,不易冲突)
组组相联映射(前两个的优化结合,先分块再分组)
替换算法
提高Cache获得尽可能高的命中率
- 随机替换
- 先进先出
- 近期最少使用
- 优化替换算法(先计算统计分析)
命中率及平均时间
尽量让CPU直接访问Cache,而不是主存。
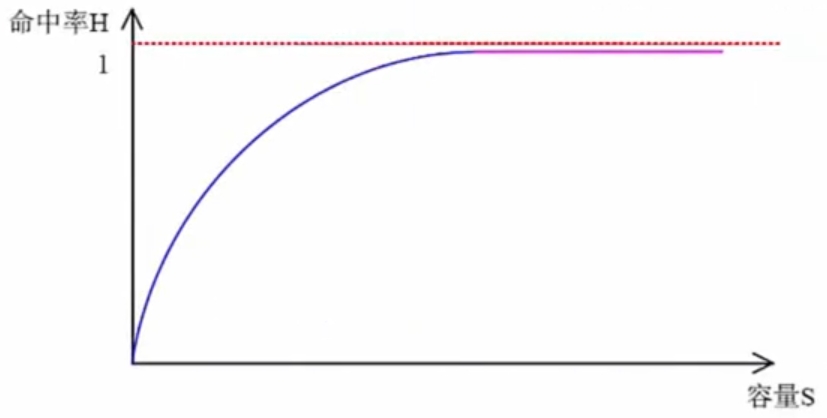
Cache有一个命中率的概念,即当CPU所访问的数据在cache中时,命中,直接从Cache中读取数据,设读取一次Cache时间为1ns,若CPU访问的数据不在cache中则需要从内存中读取,设读取一次内存的时间为1000ns,若在CPU多次读取数据过程中,有90%命中Cache,则CPU读取一次的平均时间为(90%x1+10%x1000)ns。
例题
例题①
按照cache地址映像的块冲突概率,从高到低排列的是()。
A.全相联映像→直接映像→组相联映像
B.直接映像→组相联映像→全相联映像
C.组相联映像→全相联映像→直接映像
D.直接映像→全相联映像→组相联映像
答案:B
例题②
以下关于Cache与主存间地址映射的叙述中,正确的是()。
A.操作系统负责管理Cache与主存之间的地址映射
B.程序员需要通过编程来处理cache与主存之间的地址映射
C应用软件对cache与主存之间的地址映射进行调度
D:由硬件自动完成Cache与主存之间的地址映射
答案:D
转载请注明来源,欢迎大家进行交流讨论。还可通过邮箱联系:youngdream365##qq.com (##替换为@)。

